Spark Streaming
Spark streaming是Spark核心API的一個擴充,它對即時資料串流的處理具有可擴充性、高吞吐量、可容錯性等特點。我們可以從kafka、flume、Twitter、 ZeroMQ、Kinesis等來源取得資料,也可以通過由 高階函式如map、reduce、join、window等組成的複雜演算法計算出資料。最後,處理後的資料可以推送到檔案系統、資料庫、即時儀表板中。事實上,你可以將處理後的資料應用到Spark的機器學習演算法、 圖形處理演算法中去。

在内部,它的工作原理如下圖所示。Spark Streaming接收即時的輸入資料串流,然後將這些資料切分為批次資料供Spark引擎處理,Spark引擎將資料生成最终的结果資料。
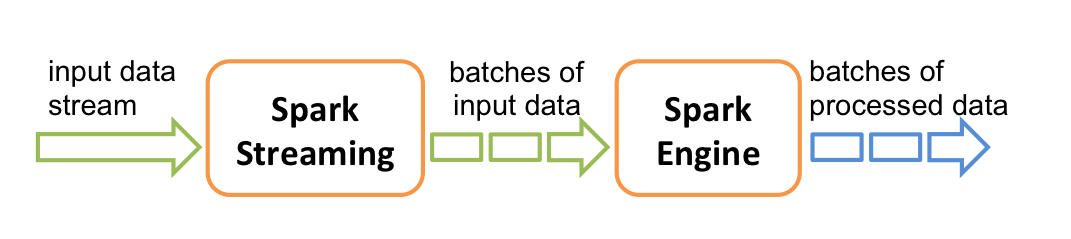
Spark Streaming支援一個高層的抽象類別類別,叫做離散化串流(discretized stream)或者DStream,它代表連續的資料串流。DStream既可以利用從Kafka, Flume和Kinesis等來源取得的輸入資料串流創建,也可以在其他DStream的基礎上藉由高階函式獲得。在内部,DStream是由一系列RDDs組成。
本指南指導使用者開始利用DStream編寫Spark Streaming程式。使用者能夠利用scala、java或者Python來編寫Spark Streaming程式。
注意:Spark 1.2已經為Spark Streaming導入了Python API。它的所有DStream transformations和幾乎所有的輸出操作可以在scala和java介面中使用。然而,它只支援基本的來源如純文字文件或者socket上 的文字資料。諸如flume、kafka等外部的來源的API會在將來導入。